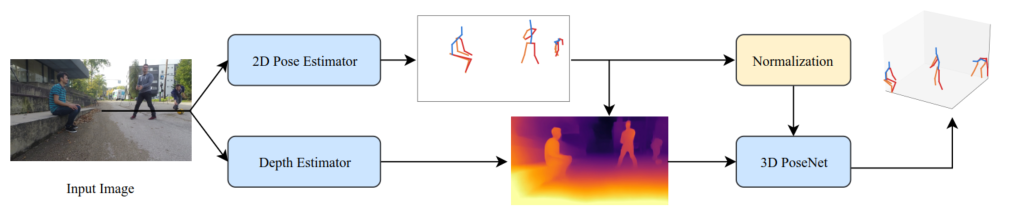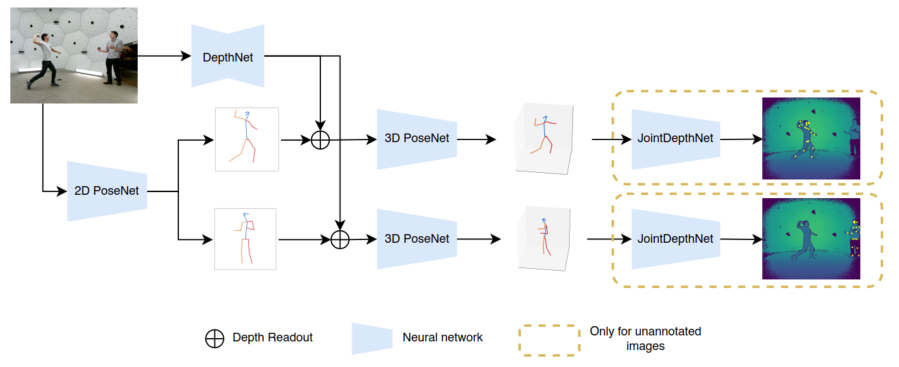
一、算法流程
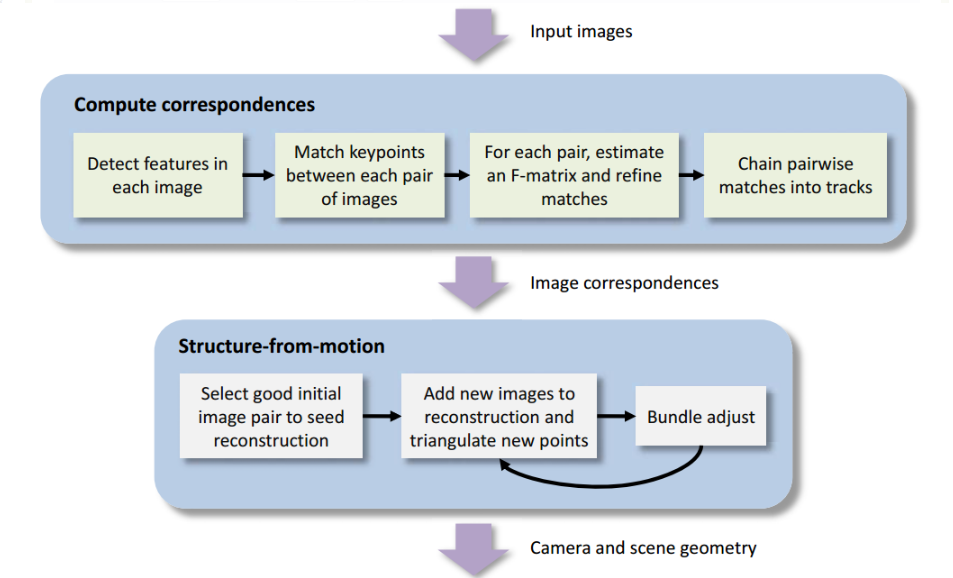
1、特征检测
SFM一般使用SIFT特征。
2、特征匹配
每张图片都进行SIFT特征检测后,我们需要将不同图片中的特征进行匹配。首先计算两张图像(如图像I和图像J)中特征之间的距离:
如果图像I中的某个特征Fi1与图像J中的特征Fj1之间的距离最小,为d1。此外,Fi1与图像J中的特征Fj2的距离d2仅次于d1。若d1/d2小于0.6,那么我们认为Fi1与Fj1是匹配点。类似的,对图像I中的每个特征都选择一个匹配点。但是我们发现,对于图像I中的每个特征,都有图像J中的唯一特征与之对应。但是对于图像J中的特征,可能存在图像I中的多个特征与之对应。因此,对这种情况需要做一次反向的筛选。最终如果一一匹配的特征数量不小于16个,那图像I和图像J可以作为初选的图像对。
匹配的所有特征对的像素坐标均需要满足对极约束,即:
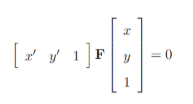
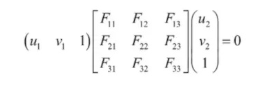
F矩阵称为基础矩阵(fundamental matrix),反映空间一点P的像素点与该点在不同视角摄像机下图像坐标系中的关系。它可以把两张图片之间的像素坐标联系起来,并包含相机的内参信息。 上述公式可以写为:
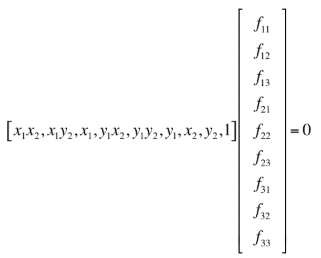
进一步,此方程如果要得到唯一解,则必须有8个匹配的特征对。

当匹配对大于8时可以使用最小二乘法计算。
但是,当匹配对中存在噪声时,F矩阵的计算会受到很大的干扰。对此前人提出过诸如加权最小二乘等方法,但是最通用的还是使用RANSAC进行数据滤除。 RANSAC在当前所有匹配对中拟合一个模型,把不符合模型的点进行滤除,以此来保证计算F矩阵的准确性。

其求解过程为:


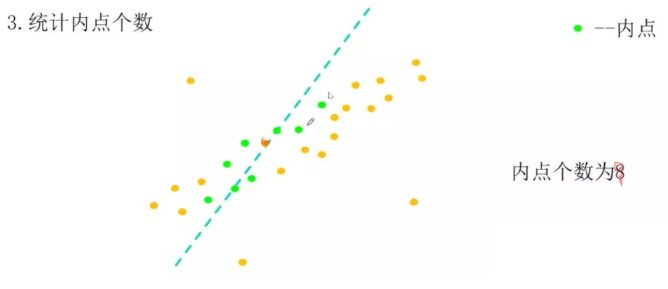
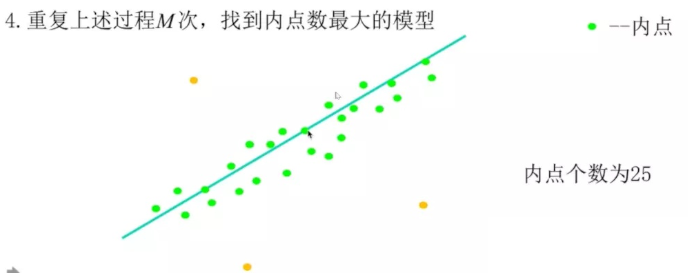
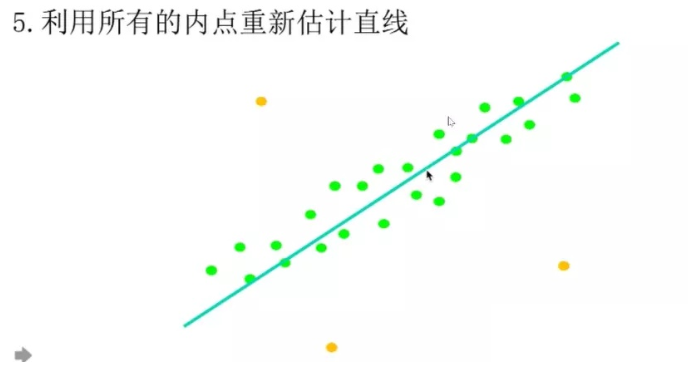
选取内点最多的对应F,这时候可以找到比较好的匹配点对了。
3、特征分解
我们求得基础矩阵F之后可以进一步得到本征矩阵E,F和E之间的关系为:
K为相机内参。 得到的本征矩阵E能够反映空间一点P的像点在不同视角摄像机下相机坐标系中的关系。(此处为三维点)
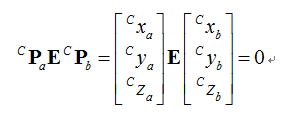
E能够分解为R和t,即相机外参中的旋转和平移。
4、SFM
获取初始的相机内外参、三维点后。利用多视角的重投影误差可以构建bundle adjustment(BA)问题,进一步优化相机参数和三维点。初始化的两帧图片可以进行第一次BA,然后不断添加新的相机和3D点进行BA。最终得到所有相机参数和估计的点云。
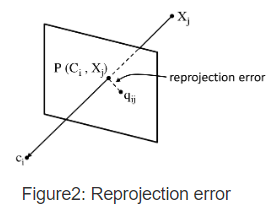
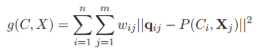
bundle adjustment实际上是一个非线性最小二乘问题,因此初始值的准确性很重要。所以为了获取准确的初始值,需要尽量多的匹配点,同时相机中心与物体之间有足够的距离。
Reference
[1] SFM算法流程
[2] 本质矩阵和基础矩阵的区别是什么?
[3] SFM算法原理初简介
[4] 计算机视觉基本原理——RANSAC
]]>

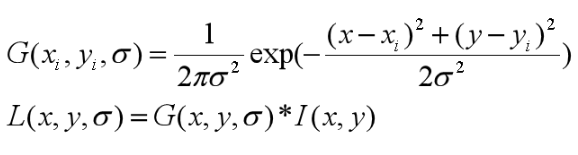






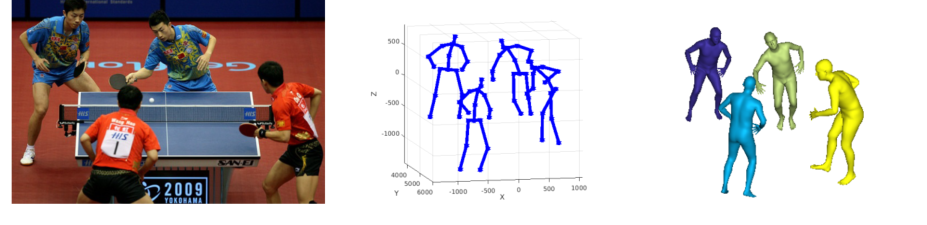
 准确的三维地平面很难通过单个视角来获取,因此本文使用了9个视角进行点采样,利用相机参数反算出三维点,然后用平面进行拟合。
准确的三维地平面很难通过单个视角来获取,因此本文使用了9个视角进行点采样,利用相机参数反算出三维点,然后用平面进行拟合。
 图中红点即为两个视角中的采样点,通过其二维坐标和相机参数能够对三维点进行解算。
图中红点即为两个视角中的采样点,通过其二维坐标和相机参数能够对三维点进行解算。